Syntax analysis or parsing is the second phase of a compiler.
A syntax analyzer or parser takes the input from a lexical analyzer in the form of token streams. The parser analyzes the source code (token stream) against the production rules to detect any errors in the code. The output of this phase is a parse tree.
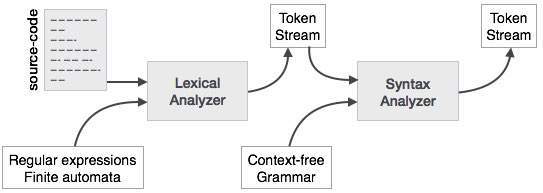
This way, the parser accomplishes two tasks, i.e., parsing the code, looking for errors and generating a parse tree as the output of the phase.
Parsers are expected to parse the whole code even if some errors exist in the program. Parsers use error recovering strategies, which we will learn later in this chapter.
Derivation
A derivation is basically a sequence of production rules, in order to get the input string. During parsing, we take two decisions for some sentential form of input:
- Deciding the non-terminal which is to be replaced.
- Deciding the production rule, by which, the non-terminal will be replaced.
To decide which non-terminal to be replaced with production rule, we can have two options.
Left-most Derivation
If the sentential form of an input is scanned and replaced from left to right, it is called left-most derivation. The sentential form derived by the left-most derivation is called the left-sentential form.
Right-most Derivation
If we scan and replace the input with production rules, from right to left, it is known as right-most derivation. The sentential form derived from the right-most derivation is called the right-sentential form.
Example
Production rules:
E → E + E E → E * E E → id
Input string: id + id * id
The left-most derivation is:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * id
Notice that the left-most side non-terminal is always processed first.
The right-most derivation is:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * id

